这两天,团队来了不少新人,有实习生也有刚毕业的大学生。看着他们稚气的面庞,文静而腼腆的样子,跟我两年前刚进公司的时候好像。今天内网提示我这是我在阿里的第732天,两周年快乐。突然觉得,我应该写点什么东西,一方面给自己一个总结,分享一下自己成长的故事。另一方面,希望能帮助刚毕业的大学生们消除一些成长路上的疑惑。

这两天,团队来了不少新人,有实习生也有刚毕业的大学生。看着他们稚气的面庞,文静而腼腆的样子,跟我两年前刚进公司的时候好像。今天内网提示我这是我在阿里的第732天,两周年快乐。突然觉得,我应该写点什么东西,一方面给自己一个总结,分享一下自己成长的故事。另一方面,希望能帮助刚毕业的大学生们消除一些成长路上的疑惑。
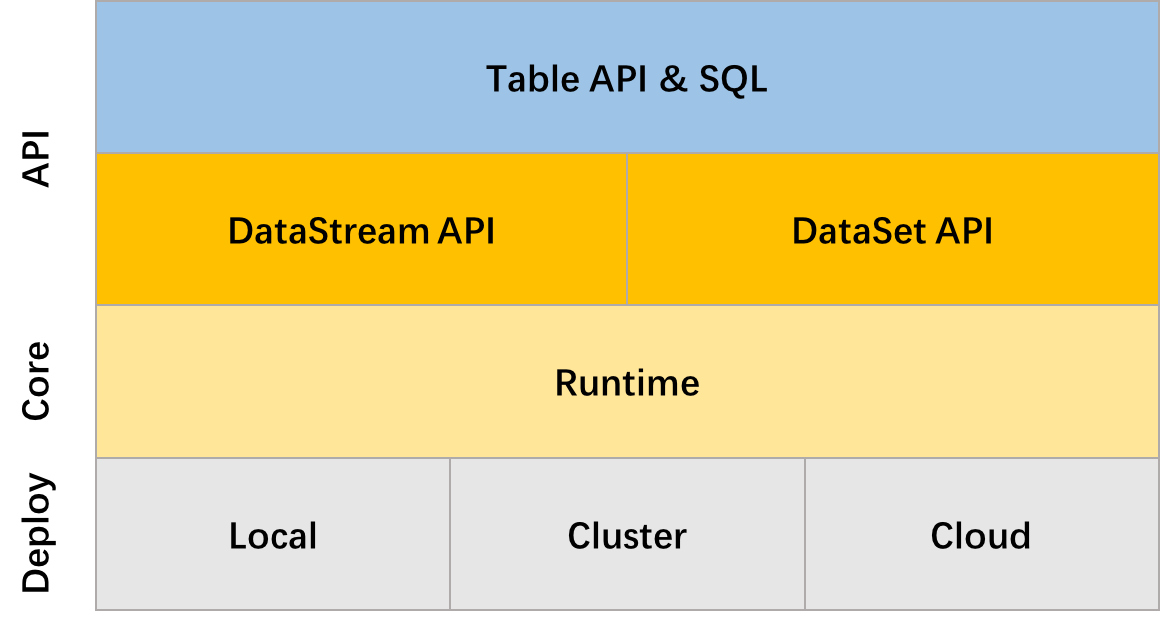
Flink 已经拥有了强大的 DataStream/DataSet API,可以基本满足流计算和批计算中的所有需求。为什么还需要 Table & SQL API 呢?
首先 Table API 是一种关系型API,类 SQL 的API,用户可以像操作表一样地操作数据,非常的直观和方便。用户只需要说需要什么东西,系统就会自动地帮你决定如何最高效地计算它,而不需要像 DataStream 一样写一大堆 Function,优化还得纯靠手工调优。另外,SQL 作为一个“人所皆知”的语言,如果一个引擎提供 SQL,它将很容易被人们接受。这已经是业界很常见的现象了。值得学习的是,Flink 的 Table API 与 SQL API 的实现,有 80% 的代码是共用的。所以当我们讨论 Table API 时,常常是指 Table & SQL API。
Table & SQL API 还有另一个职责,就是流处理和批处理统一的API层。Flink 在runtime层是统一的,因为Flink将批任务看做流的一种特例来执行,这也是 Flink 向外鼓吹的一点。然而在编程模型上,Flink 却为批和流提供了两套API (DataSet 和 DataStream)。为什么 runtime 统一,而编程模型不统一呢? 在我看来,这是本末倒置的事情。用户才不管你 runtime 层是否统一,用户更关心的是写一套代码。这也是为什么现在 Apache Beam 能这么火的原因。所以 Table & SQL API 就扛起了统一API的大旗,批上的查询会随着输入数据的结束而结束并生成有限结果集,流上的查询会一直运行并生成结果流。Table & SQL API 做到了批与流上的查询具有同样的语法,因此不用改代码就能同时在批和流上跑。
在上一篇文章:Window机制中,我们介绍了窗口的概念和底层实现,以及 Flink 一些内建的窗口,包括滑动窗口、翻滚窗口。本文将深入讲解一种较为特殊的窗口:会话窗口(session window)。建议您在阅读完上一篇文章的基础上再阅读本文。
当我们需要分析用户的一段交互的行为事件时,通常的想法是将用户的事件流按照“session”来分组。session 是指一段持续活跃的期间,由活跃间隙分隔开。通俗一点说,消息之间的间隔小于超时阈值(sessionGap)的,则被分配到同一个窗口,间隔大于阈值的,则被分配到不同的窗口。目前开源领域大部分的流计算引擎都有窗口的概念,但是没有对 session window 的支持,要实现 session window,需要用户自己去做完大部分事情。而当 Flink 1.1.0 版本正式发布时,Flink 将会是开源流计算领域第一个内建支持 session window 的引擎。
Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而窗口(window)就是从 Streaming 到 Batch 的一个桥梁。Flink 提供了非常完善的窗口机制,这是我认为的 Flink 最大的亮点之一(其他的亮点包括消息乱序处理,和 checkpoint 机制)。本文我们将介绍流式处理中的窗口概念,介绍 Flink 内建的一些窗口和 Window API,最后讨论下窗口在底层是如何实现的。
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(Time Window,例如:每30秒钟),也可以是数据驱动的(Count Window,例如:每一百个元素)。一种经典的窗口分类可以分成:翻滚窗口(Tumbling Window,无重叠),滚动窗口(Sliding Window,有重叠),和会话窗口(Session Window,活动间隙)。
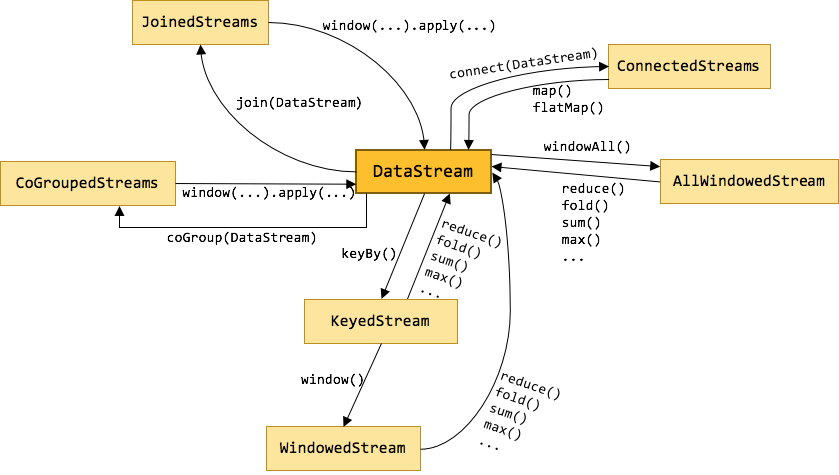
Flink 为流处理和批处理分别提供了 DataStream API 和 DataSet API。正是这种高层的抽象和 flunent API 极大地便利了用户编写大数据应用。不过很多初学者在看到官方 Streaming 文档中那一大坨的转换时,常常会蒙了圈,文档中那些只言片语也很难讲清它们之间的关系。所以本文将介绍几种关键的数据流类型,它们之间是如何通过转换关联起来的。下图展示了 Flink 中目前支持的主要几种流的类型,以及它们之间的转换关系。
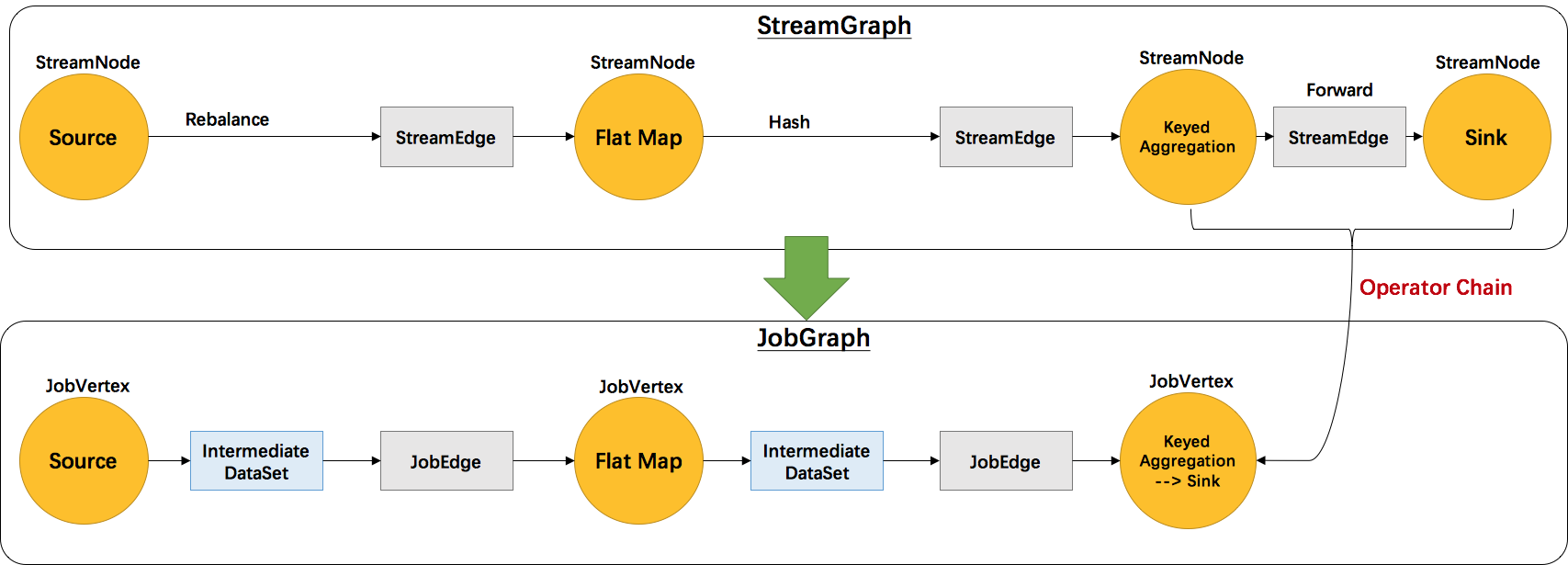
继前文Flink 原理与实现:架构和拓扑概览中介绍了Flink的四层执行图模型,本文将主要介绍 Flink 是如何将 StreamGraph 转换成 JobGraph 的。根据用户用Stream API编写的程序,构造出一个代表拓扑结构的StreamGraph的。以 WordCount 为例,转换图如下图所示:
StreamGraph 和 JobGraph 都是在 Client 端生成的,也就是说我们可以在 IDE 中通过断点调试观察 StreamGraph 和 JobGraph 的生成过程。
本文所讨论的计算资源是指用来执行 Task 的资源,是一个逻辑概念。本文会介绍 Flink 计算资源相关的一些核心概念,如:Slot、SlotSharingGroup、CoLocationGroup、Chain等。并会着重讨论 Flink 如何对计算资源进行管理和隔离,如何将计算资源利用率最大化等等。理解 Flink 中的计算资源对于理解 Job 如何在集群中运行的有很大的帮助,也有利于我们更透彻地理解 Flink 原理,更快速地定位问题。
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
继上文Flink 原理与实现:架构和拓扑概览中介绍了Flink的四层执行图模型,本文将主要介绍 Flink 是如何根据用户用Stream API编写的程序,构造出一个代表拓扑结构的StreamGraph的。
注:本文比较偏源码分析,所有代码都是基于 flink-1.0.x 版本,建议在阅读本文前先对Stream API有个了解,详见官方文档。
StreamGraph 相关的代码主要在 org.apache.flink.streaming.api.graph 包中。构造StreamGraph的入口函数是 StreamGraphGenerator.generate(env, transformations)。该函数会由触发程序执行的方法StreamExecutionEnvironment.execute()调用到。也就是说 StreamGraph 是在 Client 端构造的,这也意味着我们可以在本地通过调试观察 StreamGraph 的构造过程。
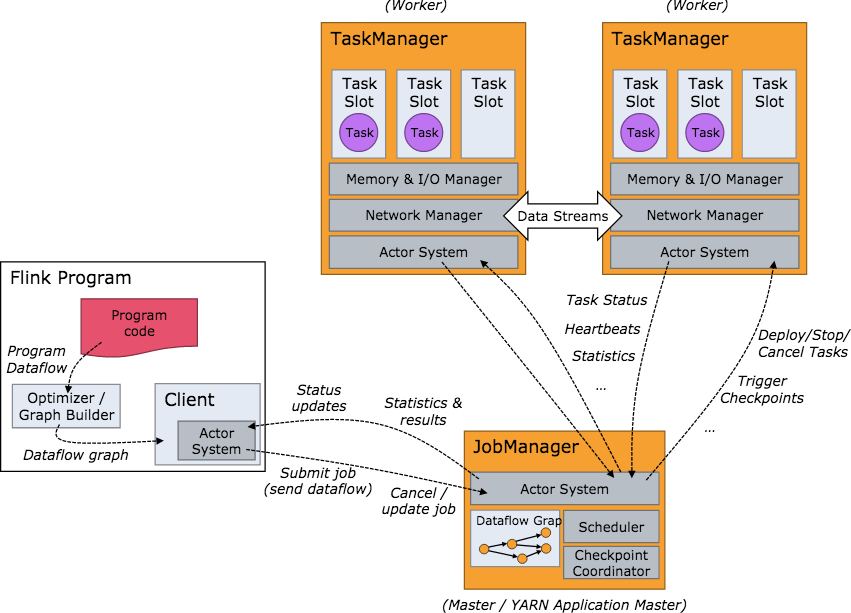
要了解一个系统,一般都是从架构开始。我们关心的问题是:系统部署成功后各个节点都启动了哪些服务,各个服务之间又是怎么交互和协调的。下方是 Flink 集群启动后架构图。
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。