上周四在 Flink 中文社区钉钉群中直播分享了《Demo:基于 Flink SQL 构建流式应用》,直播内容偏向实战演示。这篇文章是对直播内容的一个总结,并且改善了部分内容,比如除 Flink 外其他组件全部采用 Docker Compose 安装,简化准备流程。读者也可以结合视频和本文一起学习。完整分享可以观看视频回顾:https://www.bilibili.com/video/av90560012
Flink 1.10.0 于近期刚发布,释放了许多令人激动的新特性。尤其是 Flink SQL 模块,发展速度非常快,因此本文特意从实践的角度出发,带领大家一起探索使用 Flink SQL 如何快速构建流式应用。
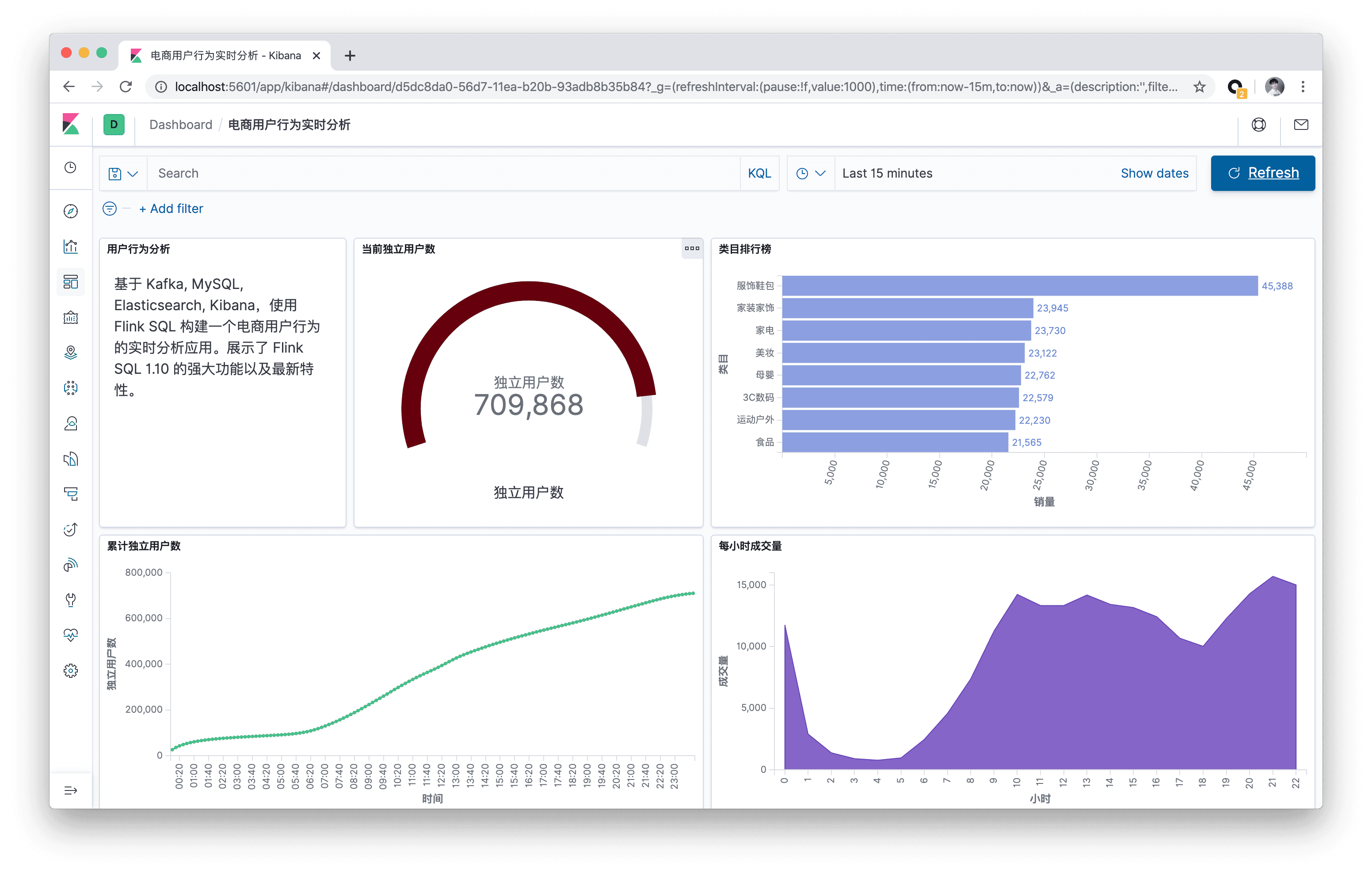
本文将基于 Kafka, MySQL, Elasticsearch, Kibana,使用 Flink SQL 构建一个电商用户行为的实时分析应用。本文所有的实战演练都将在 Flink SQL CLI 上执行,全程只涉及 SQL 纯文本,无需一行 Java/Scala 代码,无需安装 IDE。本实战演练的最终效果图:
准备
一台装有 Docker 和 Java8 的 Linux 或 MacOS 计算机。
使用 Docker Compose 启动容器
本实战演示所依赖的组件全都编排到了容器中,因此可以通过 docker-compose 一键启动。你可以通过 wget 命令自动下载该 docker-compose.yml 文件,也可以手动下载。
mkdir flink-demo; cd flink-demo; |
该 Docker Compose 中包含的容器有:
- DataGen: 数据生成器。容器启动后会自动开始生成用户行为数据,并发送到 Kafka 集群中。默认每秒生成 1000 条数据,持续生成约 3 小时。也可以更改
docker-compose.yml中 datagen 的speedup参数来调整生成速率(重启 docker compose 才能生效)。 - MySQL: 集成了 MySQL 5.7 ,以及预先创建好了类目表(
category),预先填入了子类目与顶级类目的映射关系,后续作为维表使用。 - Kafka: 主要用作数据源。DataGen 组件会自动将数据灌入这个容器中。
- Zookeeper: Kafka 容器依赖。
- Elasticsearch: 主要存储 Flink SQL 产出的数据。
- Kibana: 可视化 Elasticsearch 中的数据。
在启动容器前,建议修改 Docker 的配置,将资源调整到 4GB 以及 4核。启动所有的容器,只需要在 docker-compose.yml 所在目录下运行如下命令。
docker-compose up -d |
该命令会以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。你可以通过 docker ps 来观察上述的五个容器是否正常启动了。 也可以访问 http://localhost:5601/ 来查看 Kibana 是否运行正常。
另外可以通过如下命令停止所有的容器:
docker-compose down |
下载安装 Flink 本地集群
我们推荐用户手动下载安装 Flink,而不是通过 Docker 自动启动 Flink。因为这样可以更直观地理解 Flink 的各个组件、依赖、和脚本。
- 下载 Flink 1.10.0 安装包并解压(解压目录
flink-1.10.0):https://www.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz - 进入 flink-1.10.0 目录:
cd flink-1.10.0 通过如下命令下载依赖 jar 包,并拷贝到
lib/目录下,也可手动下载和拷贝。因为我们运行时需要依赖各个 connector 实现。wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-json/1.10.0/flink-json-1.10.0.jar | \
wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.10.0/flink-sql-connector-kafka_2.11-1.10.0.jar | \
wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-elasticsearch6_2.11/1.10.0/flink-sql-connector-elasticsearch6_2.11-1.10.0.jar | \
wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.10.0/flink-jdbc_2.11-1.10.0.jar | \
wget -P ./lib/ https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.48/mysql-connector-java-5.1.48.jar将
conf/flink-conf.yaml中的taskmanager.numberOfTaskSlots修改成 10,因为我们会同时运行多个任务。- 执行
./bin/start-cluster.sh,启动集群。
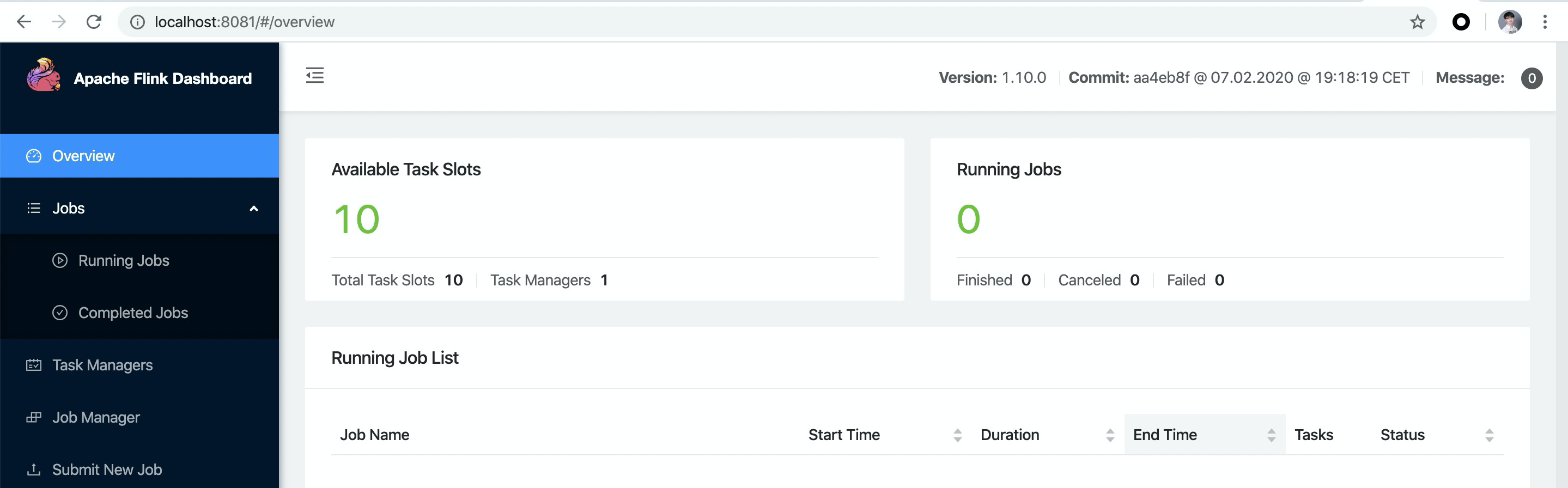
运行成功的话,可以在 http://localhost:8081 访问到 Flink Web UI。并且可以看到可用 Slots 数为 10 个。
- 执行
bin/sql-client.sh embedded启动 SQL CLI。便会看到如下的松鼠欢迎界面。
使用 DDL 创建 Kafka 表
Datagen 容器在启动后会往 Kafka 的 user_behavior topic 中持续不断地写入数据。数据包含了2017年11月27日一天的用户行为(行为包括点击、购买、加购、喜欢),每一行表示一条用户行为,以 JSON 的格式由用户ID、商品ID、商品类目ID、行为类型和时间组成。该原始数据集来自阿里云天池公开数据集,特此鸣谢。
我们可以在 docker-compose.yml 所在目录下运行如下命令,查看 Kafka 集群中生成的前10条数据。
docker-compose exec kafka bash -c 'kafka-console-consumer.sh --topic user_behavior --bootstrap-server kafka:9094 --from-beginning --max-messages 10' |
{"user_id": "952483", "item_id":"310884", "category_id": "4580532", "behavior": "pv", "ts": "2017-11-27T00:00:00Z"} |
有了数据源后,我们就可以用 DDL 去创建并连接这个 Kafka 中的 topic 了。在 Flink SQL CLI 中执行该 DDL。
CREATE TABLE user_behavior ( |
如上我们按照数据的格式声明了 5 个字段,除此之外,我们还通过计算列语法和 PROCTIME() 内置函数声明了一个产生处理时间的虚拟列。我们还通过 WATERMARK 语法,在 ts 字段上声明了 watermark 策略(容忍5秒乱序), ts 字段因此也成了事件时间列。关于时间属性以及 DDL 语法可以阅读官方文档了解更多:
- 时间属性:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/streaming/time_attributes.html - DDL:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sql/create.html#create-table
在 SQL CLI 中成功创建 Kafka 表后,可以通过 show tables; 和 describe user_behavior; 来查看目前已注册的表,以及表的详细信息。我们也可以直接在 SQL CLI 中运行 SELECT * FROM user_behavior; 预览下数据(按q退出)。
接下来,我们会通过三个实战场景来更深入地了解 Flink SQL 。
统计每小时的成交量
使用 DDL 创建 Elasticsearch 表
我们先在 SQL CLI 中创建一个 ES 结果表,根据场景需求主要需要保存两个数据:小时、成交量。
CREATE TABLE buy_cnt_per_hour ( |
我们不需要在 Elasticsearch 中事先创建 buy_cnt_per_hour 索引,Flink Job 会自动创建该索引。
提交 Query
统计每小时的成交量就是每小时共有多少 “buy” 的用户行为。因此会需要用到 TUMBLE 窗口函数,按照一小时切窗。然后每个窗口分别统计 “buy” 的个数,这可以通过先过滤出 “buy” 的数据,然后 COUNT(*) 实现。
INSERT INTO buy_cnt_per_hour |
这里我们使用 HOUR 内置函数,从一个 TIMESTAMP 列中提取出一天中第几个小时的值。使用了 INSERT INTO将 query 的结果持续不断地插入到上文定义的 es 结果表中(可以将 es 结果表理解成 query 的物化视图)。另外可以阅读该文档了解更多关于窗口聚合的内容:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sql/queries.html#group-windows
在 Flink SQL CLI 中运行上述查询后,在 Flink Web UI 中就能看到提交的任务,该任务是一个流式任务,因此会一直运行。
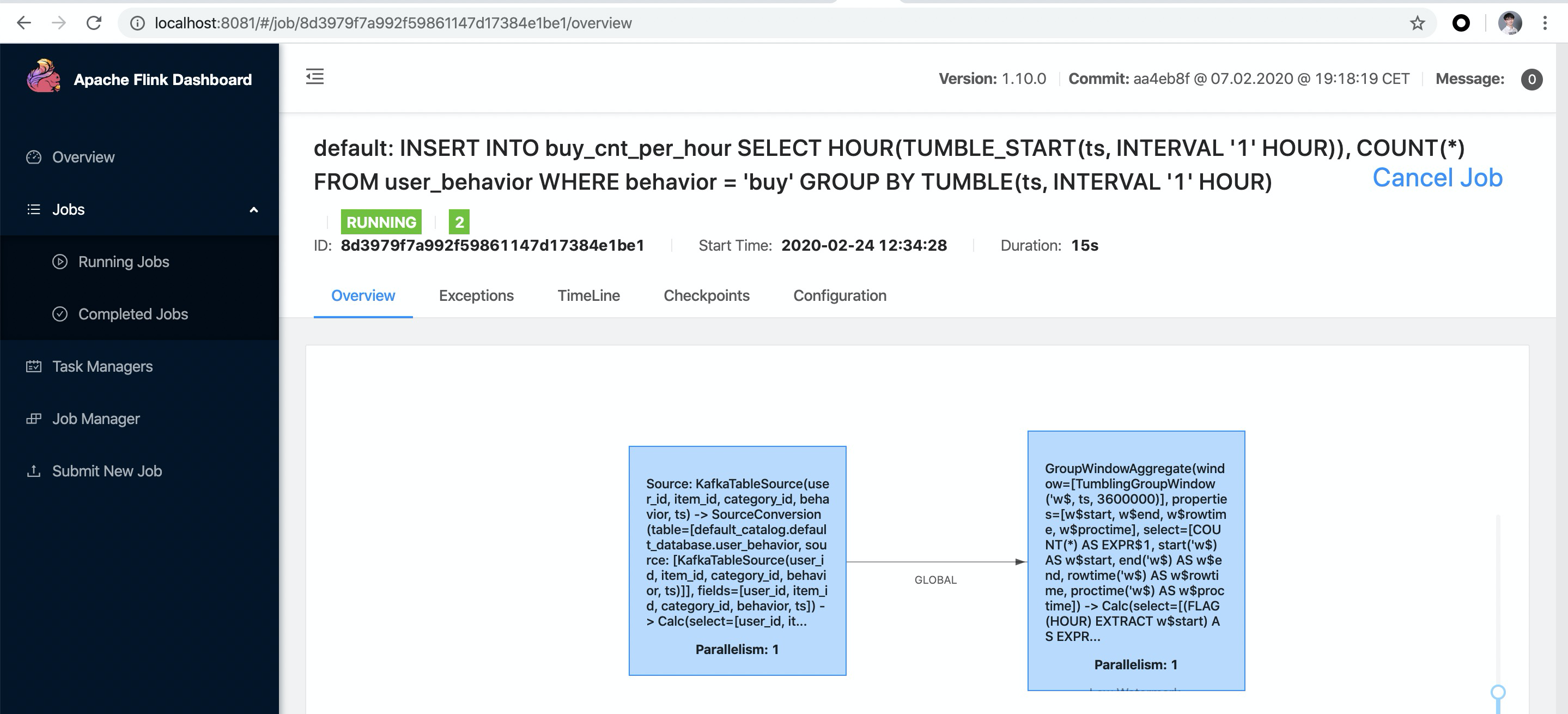
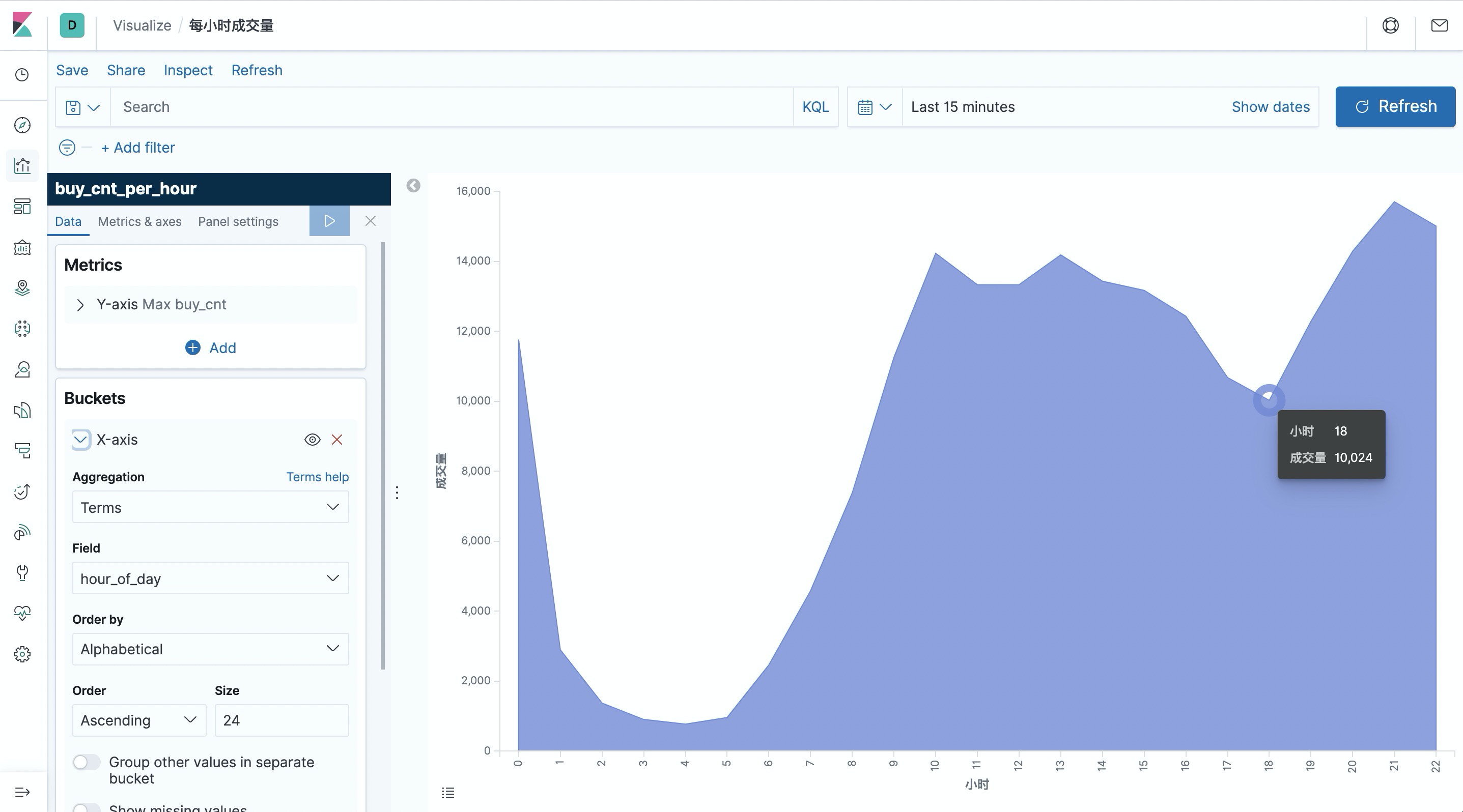
可以看到凌晨是一天中成交量的低谷。
使用 Kibana 可视化结果
我们已经通过 Docker Compose 启动了 Kibana 容器,可以通过 http://localhost:5601 访问 Kibana。首先我们需要先配置一个 index pattern。点击左侧工具栏的 “Management”,就能找到 “Index Patterns”。点击 “Create Index Pattern”,然后通过输入完整的索引名 “buy_cnt_per_hour” 创建 index pattern。创建完成后, Kibana 就知道了我们的索引,我们就可以开始探索数据了。
先点击左侧工具栏的”Discovery”按钮,Kibana 就会列出刚刚创建的索引中的内容。
接下来,我们先创建一个 Dashboard 用来展示各个可视化的视图。点击页面左侧的”Dashboard”,创建一个名为 ”用户行为日志分析“ 的Dashboard。然后点击 “Create New” 创建一个新的视图,选择 “Area” 面积图,选择 “buy_cnt_per_hour” 索引,按照如下截图中的配置(左侧)画出成交量面积图,并保存为”每小时成交量“。
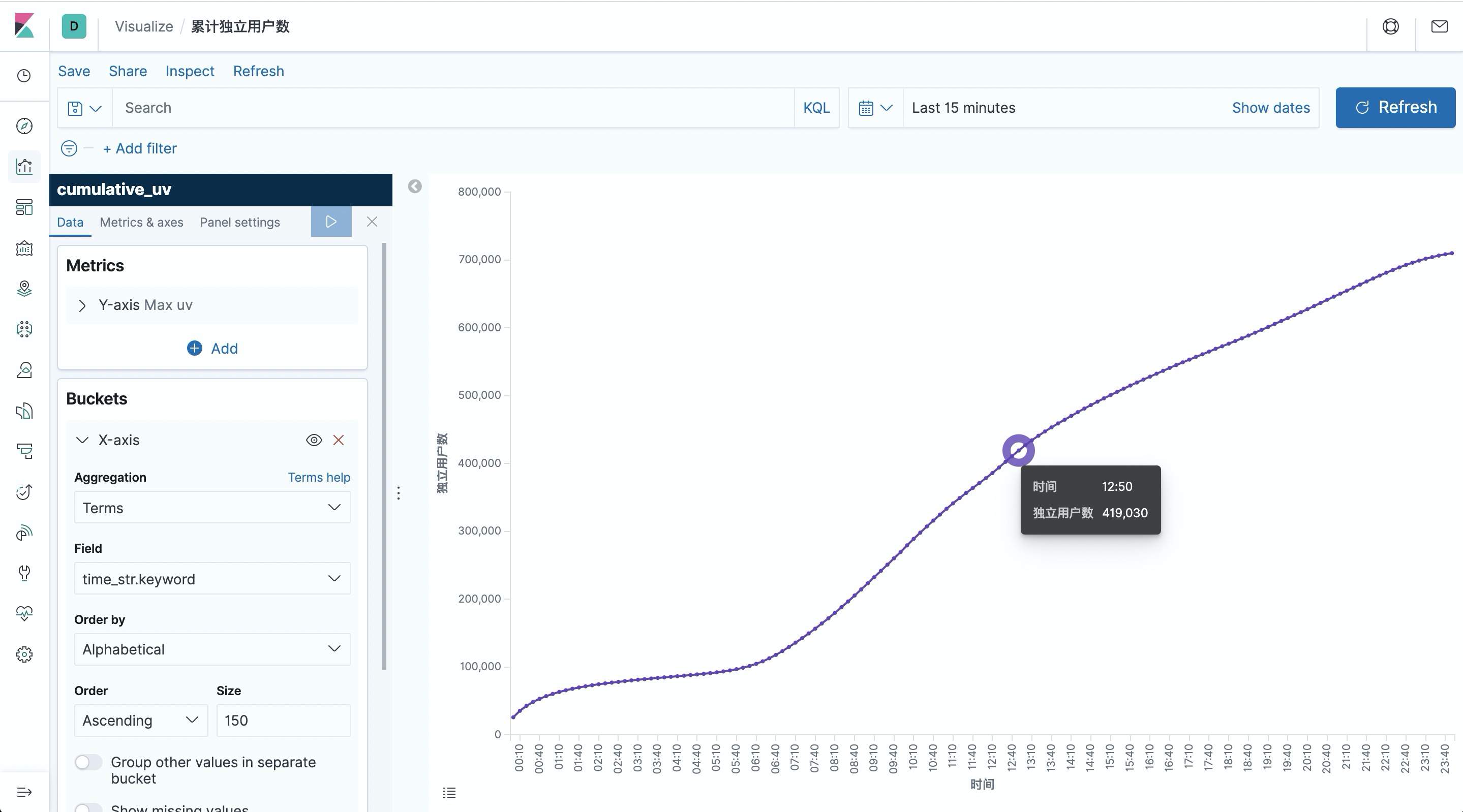
统计一天每10分钟累计独立用户数
另一个有意思的可视化是统计一天中每一刻的累计独立用户数(uv),也就是每一刻的 uv 数都代表从0点到当前时刻为止的总计 uv 数,因此该曲线肯定是单调递增的。
我们仍然先在 SQL CLI 中创建一个 Elasticsearch 表,用于存储结果汇总数据。主要有两个字段:时间和累积 uv 数。
CREATE TABLE cumulative_uv ( |
为了实现该曲线,我们可以先通过 OVER WINDOW 计算出每条数据的当前分钟,以及当前累计 uv(从0点开始到当前行为止的独立用户数)。 uv 的统计我们通过内置的 COUNT(DISTINCT user_id)来完成,Flink SQL 内部对 COUNT DISTINCT 做了非常多的优化,因此可以放心使用。
CREATE VIEW uv_per_10min AS |
这里我们使用 SUBSTR 和 DATE_FORMAT 还有 || 内置函数,将一个 TIMESTAMP 字段转换成了 10分钟单位的时间字符串,如: 12:10, 12:20。关于 OVER WINDOW 的更多内容可以参考文档:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sql/queries.html#aggregations
我们还使用了 CREATE VIEW 语法将 query 注册成了一个逻辑视图,可以方便地在后续查询中对该 query 进行引用,这有利于拆解复杂 query。注意,创建逻辑视图不会触发作业的执行,视图的结果也不会落地,因此使用起来非常轻量,没有额外开销。由于 uv_per_10min 每条输入数据都产生一条输出数据,因此对于存储压力较大。我们可以基于 uv_per_10min 再根据分钟时间进行一次聚合,这样每10分钟只有一个点会存储在 Elasticsearch 中,对于 Elasticsearch 和 Kibana 可视化渲染的压力会小很多。
INSERT INTO cumulative_uv |
提交上述查询后,在 Kibana 中创建 cumulative_uv 的 index pattern,然后在 Dashboard 中创建一个”Line”折线图,选择 cumulative_uv 索引,按照如下截图中的配置(左侧)画出累计独立用户数曲线,并保存。
顶级类目排行榜
最后一个有意思的可视化是类目排行榜,从而了解哪些类目是支柱类目。不过由于源数据中的类目分类太细(约5000个类目),对于排行榜意义不大,因此我们希望能将其归约到顶级类目。所以笔者在 mysql 容器中预先准备了子类目与顶级类目的映射数据,用作维表。
在 SQL CLI 中创建 MySQL 表,后续用作维表查询。
CREATE TABLE category_dim ( |
同时我们再创建一个 Elasticsearch 表,用于存储类目统计结果。
CREATE TABLE top_category ( |
第一步我们通过维表关联,补全类目名称。我们仍然使用 CREATE VIEW 将该查询注册成一个视图,简化逻辑。维表关联使用 temporal join 语法,可以查看文档了解更多:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/streaming/joins.html#join-with-a-temporal-table
CREATE VIEW rich_user_behavior AS |
最后根据 类目名称分组,统计出 buy 的事件数,并写入 Elasticsearch 中。
INSERT INTO top_category |
提交上述查询后,在 Kibana 中创建 top_category 的 index pattern,然后在 Dashboard 中创建一个”Horizontal Bar”条形图,选择 top_category 索引,按照如下截图中的配置(左侧)画出类目排行榜,并保存。
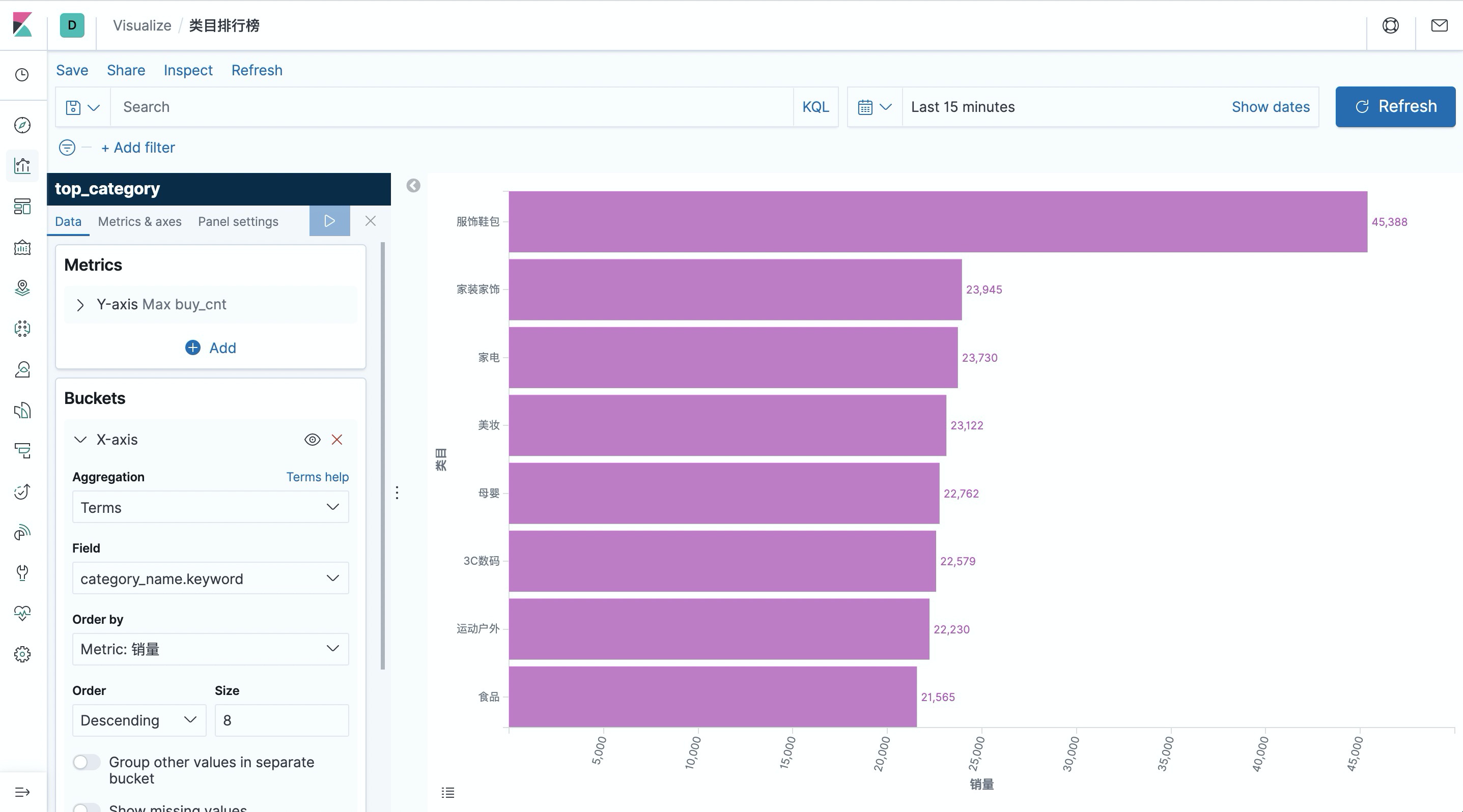
可以看到服饰鞋包的成交量远远领先其他类目。
Kibana 还提供了非常丰富的图形和可视化选项,感兴趣的用户可以用 Flink SQL 对数据进行更多维度的分析,并使用 Kibana 展示出可视化图,并观测图形数据的实时变化。
结尾
在本文中,我们展示了如何使用 Flink SQL 集成 Kafka, MySQL, Elasticsearch 以及 Kibana 来快速搭建一个实时分析应用。整个过程无需一行 Java/Scala 代码,使用 SQL 纯文本即可完成。期望通过本文,可以让读者了解到 Flink SQL 的易用和强大,包括轻松连接各种外部系统、对事件时间和乱序数据处理的原生支持、维表关联、丰富的内置函数等等。希望你能喜欢我们的实战演练,并从中获得乐趣和知识!
