Flink 1.16:Hive SQL 如何平迁到 Flink SQL
本文整理自我在 9 月 24 日 Apache Flink Meetup 北京站的演讲。主要内容包括:Hive SQL 迁移的动机、挑战、实践、演示和未来规划。
上周四在 Flink 中文社区钉钉群中直播分享了《Demo:基于 Flink SQL 构建流式应用》,直播内容偏向实战演示。这篇文章是对直播内容的一个总结,并且改善了部分内容,比如除 Flink 外其他组件全部采用 Docker Compose 安装,简化准备流程。读者也可以结合视频和本文一起学习。完整分享可以观看视频回顾:https://www.bilibili.com/video/av90560012
Flink 1.10.0 于近期刚发布,释放了许多令人激动的新特性。尤其是 Flink SQL 模块,发展速度非常快,因此本文特意从实践的角度出发,带领大家一起探索使用 Flink SQL 如何快速构建流式应用。
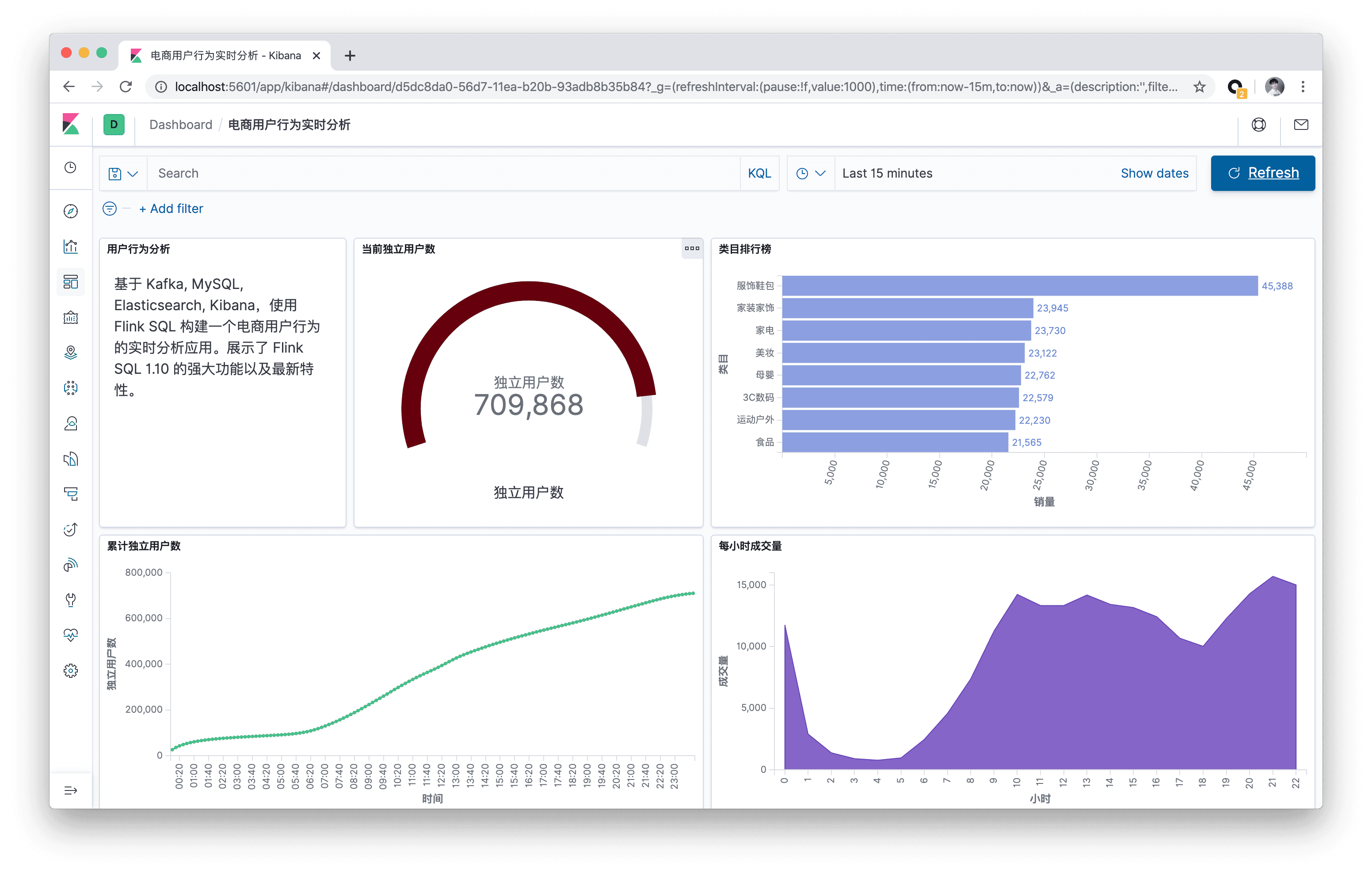
本文将基于 Kafka, MySQL, Elasticsearch, Kibana,使用 Flink SQL 构建一个电商用户行为的实时分析应用。本文所有的实战演练都将在 Flink SQL CLI 上执行,全程只涉及 SQL 纯文本,无需一行 Java/Scala 代码,无需安装 IDE。本实战演练的最终效果图:
上周六在深圳分享了《Flink SQL 1.9.0 技术内幕和最佳实践》,会后许多小伙伴对最后演示环节的 Demo 代码非常感兴趣,迫不及待地想尝试下,所以写了这篇文章分享下这份代码。希望对于 Flink SQL 的初学者能有所帮助。完整分享可以观看 Meetup 视频回顾 :https://developer.aliyun.com/live/1416
演示代码已经开源到了 GitHub 上:https://github.com/wuchong/flink-sql-submit 。
这份代码主要由两部分组成:1) 能用来提交 SQL 文件的 SqlSubmit 实现。2) 用于演示的 SQL 示例、Kafka 启动停止脚本、 一份测试数据集、Kafka 数据源生成器。
通过本实战,你将学到:
注: 本教程实践基于 Ververica 开源的 sql-training 项目。基于 Flink 1.7.2 。
本文将通过五个实例来贯穿 Flink SQL 的编程实践,主要会涵盖以下几个方面的内容。
本文假定您已具备基础的 SQL 知识。
过去三年,我一直在为 Apache Flink 开源项目贡献,也在两年前成为了 Flink Committer。我在 Flink 社区成长的过程中受到过社区大神的很多指导,如今也有很多人在向我咨询如何能参与到开源社区中,如何能成为 Committer。这也是本文写作的初衷,希望能帮助更多人参与到开源社区中。
本文将以 Apache Flink 为例,介绍如何参与社区贡献,如何成为 Apache Committer。